ES9 is the current version of the specification.
ES10 is still a draft.
Today in Stage 4 there are only a few proposals, but in Stage 3 - a whole dozen!
Five stages
| Stage | Name | Description |
|---|---|---|
| 0 | Strawman | An idea that can be implemented through the Babel plugin |
| 1 | Proposal | A formal proposal for the feature and check the viability of the idea |
| 2 | Draft | Start developing specifications |
| 3 | Candidate | A preliminary version of the specification |
| 4 | Finished | The final version of the specification |
Note: to ensure the stability of the application, only Stage 3 and higher should be used.
In this article, we will only look at Stage 4 (de facto, included in the new standard) and Stage 3 (which is about to become a part of it).
Stage 4
These changes are already included in the standard.
Optional argument of catch
Before ES10, a catch block forced us to bind an exception variable for the catch clause whether it’s necessary or not:
function isValidJSON(text) {
try {
JSON.parse(text);
return true;
} catch (unused) { // variable is not used
return false;
}
}Sometimes, as we see above, the exception variable that’s bound to the catch clause is absolutely redundant.
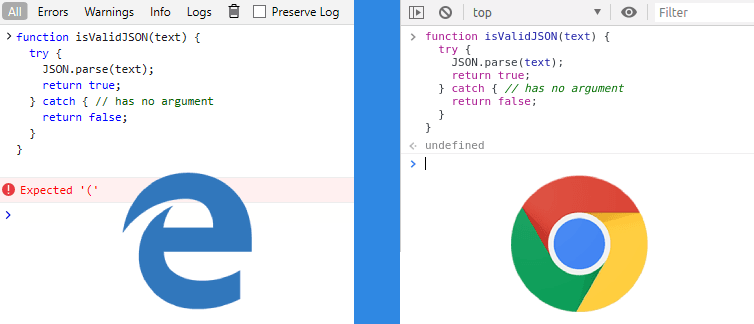
Starting from the ES10 edition, the parentheses can be omitted and the catch will looks like try as two peas in a pod:
function isValidJSON(text) {
try {
JSON.parse(text);
return true;
} catch { // has no argument
return false;
}
}Access to the symbolic link description
The symbolic link description can be indirectly obtained by the toString() method:
const symLink = Symbol("Symbol description");
String(symLink);
// ↪ "Symbol(Symbol description)"Starting with ES10, symbols will have a description property that is read-only. It allows you to get a description of the symbol without any dancing with a tambourine:
symLink.description;
// ↪ "Symbol description"If the description is not specified, undefined will be returned:
const withoutDescriptionSymbol = Symbol();
withoutDescriptionSymbol.description;
// ↪ undefined
const emptyDescriptionSymbol = Symbol('');
emptyDescriptionSymbol.description;
// ↪ ""EcmaScript strings compatible with JSON
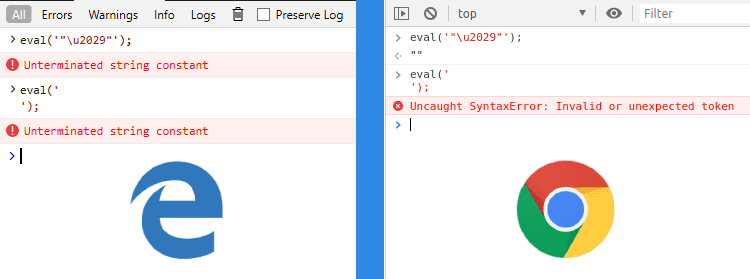
EcmaScript before its 10th edition, claims that ECMAScript JSON is a subset of JSON, but that's not entirely true. Whereas JSON strings accepts unescaped line separator U+2028 and paragraph separator U+2029 characters, but ECMAScript strings up to version 10 don't accept.
If you call eval() with the string "u2029", it behaves as if we had done a line break - right in the middle of the code, but with ES10 strings it is fine now:
Function prototype toString() revision
Goals of changes
- remove the forward-incompatible requirement:
If the implementation cannot produce a source code string that meets these criteria then it must return a string for which
evalwill throw a SyntaxError exception.
- clarify the "functionally equivalent" requirement
- standardise the string representation of built-in functions and host objects
- clarify requirement of representation based on the "actual characteristics" of an object
- ensure that the string's parse contains the same function body and parameter list as the original
- for functions defined using ECMAScript code,
toStringmust return source text slice from beginning of first token to end of last token matched by the appropriate grammar production - for built-in function objects and bound function exotic objects,
toStringmust not return anything other thanNativeFunction - for callable objects which were not defined using ECMAScript code,
toStringmust returnNativeFunction - for functions created dynamically (through the Function and GeneratorFunction constructors),
toStringmust synthesise a source text - for all other objects,
toStringmust throw a TypeError exception
// User-defined function
function () { console.log('My Function!'); }.toString();
// ↪ function () { console.log('My Function!'); }
// Embedded object method
Number.parseInt.toString();
// ↪ function parseInt() { [native code] }
// Function with context binding
function () { }.bind(0).toString();
// ↪ function () { [native code] }
// Built-in callable function object
Symbol.toString();
// ↪ function Symbol() { [native code] }
// Dynamically generated function object
Function().toString();
// ↪ function anonymous() {}
// Dynamically generated function generator-object
function* () { }.toString();
// ↪ function* () { }
// .call is now waiting for the function as an argument
Function.prototype.toString.call({});
// ↪ Function.prototype.toString requires that 'this' be a Function"Stage 3
Proposals that came out of the draft status, but not yet included in the final version of the standard.
private / static / public methods, properties and attributes for classes
TC39 proposal reference for class fieldsTC39 proposal reference for private methodsTC39 proposal reference for static class features
In some languages there is an agreement to call private methods through an underscore.
class Person:
def __init__(self, name, alias):
self.name = name # public
self.__alias = alias # private
def who(self):
print('name : ', self.name)
print('alias : ', self.__alias)
def __foo(self): # private method
print('This is private method')
def foo(self): # public method
print('This is public method')
self.__foo()But let me remind you - this is only an agreement. Nothing prevents you from using the prefix for other purposes, using another prefix, or not using it at all. The developers of the EcmaScript specification went further and made the # sign (hash, octothorp) part of the syntax. To make methods, getter/setters or fields private, just give them a name starting with #.
With all of its implementation kept internal to the class, this custom element can present an interface which is basically just like a built-in HTML element. Users of the custom element don't have the power to mess around with any of its internals.
class Counter extends HTMLElement {
#xValue = 0;
get #x() {
return #xValue;
}
set #x(value) {
this.#xValue = value;
window.requestAnimationFrame(this.#render.bind(this));
}
#clicked() {
this.#x++;
}
constructor() {
super();
this.onclick = this.#clicked.bind(this);
}
connectedCallback() {
this.#render();
}
#render() {
this.textContent = this.#x.toString();
}
}
window.customElements.define('num-counter', Counter);Like static public methods, static public fields take a common idiom which was possible to write without class syntax and make it more ergonomic, have more declarative-feeling syntax (although the semantics are quite imperative), and allow free ordering with other class elements.
Declaring static properties in the class body is hoped to be cleaner and doing a better job of meeting programmer expectations of what classes should be for. The latter workaround is a somewhat common idiom, and it would be a nice convenience for programmers if the property declaration could be lifted into the class body, matching how methods are placed there.
Hashbang (shebang) Grammar
Shebang (hashbang) is a familiar way for *nix users to specify an interpreter for an executable file.
Some CLI JS hosts strip the hashbang in order to generate valid JS source texts before passing to JS engines currently. This would unify and standardize how that is done.
#!/usr/bin/env node
// in the Script Goal
'use strict';
console.log(1);#!/usr/bin/env node
// in the Module Goal
export {};
console.log(1);Under Unix-like operating systems, when a script with a shebang is run as a program, the program loader parses the rest of the script's initial line as an interpreter directive; the specified interpreter program is run instead, passing to it as an argument the path that was initially used when attempting to run the script.
So, the index.js file can be executed in the shell, like an executable (if it has executable permission):
$ ./index.jsinstead of
$ node index.jsBigInt: Arbitrary precision integers

BigInt is a new primitive that provides a way to represent whole numbers larger than 253, which is the largest number Javascript can reliably represent with the Number primitive.
const x = Number.MAX_SAFE_INTEGER;
// ↪ 9007199254740991, this is 1 less than 2^53
const y = x + 1;
// ↪ 9007199254740992, ok, checks out
const z = x + 2
// ↪ 9007199254740992, wait, that’s the same as above!A BigInt is created by appending n to the end of the integer or by calling the constructor.
const theBiggestInt = 9007199254740991n;
const alsoHuge = BigInt(9007199254740991);
// ↪ 9007199254740991n
const hugeButString = BigInt('9007199254740991');
// ↪ 9007199254740991n
This is a new primitive type:
typeof 123;
// ↪ 'number'
typeof 123n;
// ↪ 'bigint'Numbers and BigInts may be compared as usual.
42n === BigInt(42);
// ↪ true
42n == 42;
// ↪ trueBut mathematical operations need to be carried out within one type:
20000000000000n / 20n
// ↪ 1000000000000n
20000000000000n / 20
// ↪ Uncaught TypeError: Cannot mix BigInt and other types, use explicit conversionsUnary minus is supported, unary plus returns an error:
-2n
// ↪ -2n
+2n
// ↪ Uncaught TypeError: Cannot convert a BigInt value to a numberglobalThis - a new way to access the global context
Since the implementation of the global scope is dependent on a particular engine, you had to do something like this before:
var getGlobal = function () {
// the only reliable means to get the global object is
// `Function('return this')()`
// However, this causes CSP violations in Chrome apps.
if (typeof self !== 'undefined') { return self; }
if (typeof window !== 'undefined') { return window; }
if (typeof global !== 'undefined') { return global; }
throw new Error('unable to locate global object');
};And even this option did not guarantee that everything will work exactly. globalThis is a common way for all platforms to access the global scope:
// Appeal to the global array constructor
globalThis.Array(1,2,3);
// ↪ [1, 2, 3]
// Write data to the global scope
globalThis.myGLobalSettings = {
isActive: true
};
// Access data from the global scope
globalThis.myGLobalSettings;
// ↪ {isActive: true}Dynamic import()

Did you want variables in the import strings? With dynamic imports, this has become possible:
import(`./language-packs/${navigator.language}.js`);Dynamic import is an asynchronous operation. It returns a Promise that, after loading a module, returns it to the callback function. Therefore, new binding would work only inside async functions:
element.addEventListener('click', async () => {
const module = await import(`./eventsScripts/buttonClickEvent.js`);
module.clickEvent();
});It looks like a call to the import() function, but is not inherited from Function.prototype, which means it will not be possible to call via call or apply:
import.call("example this", "argument")
// ↪ Uncaught SyntaxError: Unexpected identifierimport.meta - meta-information about the loaded module
In the code of the loadable module it became possible to obtain information on it. For now it is only the address from where the module was loaded:
console.log(import.meta);
// ↪ { url: "file:///home/user/my-module.js" }Creating an object using Object.fromEntries()
Object.fromEntries is proposed to perform the reverse of Object.entries: it accepts an iterable of key-value pairs and returns a new object whose own keys and corresponding values are given by those pairs.
Object.fromEntries([['key1', 1], ['key2', 2]])
// ↪ {key1: 1; key2: 2}Underscore and Lodash provide a _.fromPairs function which constructs an object from a list of key-value pairs.
Well-formed JSON.stringify
RFC 8259 section 8.1 requires JSON text exchanged outside the scope of a closed ecosystem to be encoded using UTF-8, but JSON.stringify can return strings including code points that have no representation in UTF-8 (specifically, surrogate code points U+D800 through U+DFFF).
// Non-BMP characters still serialize to surrogate pairs.
JSON.stringify('𝌆')
// ↪ '"𝌆"'
JSON.stringify('uD834uDF06')
// ↪ '"𝌆"'
// Unpaired surrogate code units will serialize to escape sequences.
JSON.stringify('uDF06uD834')
// ↪ '"\udf06\ud834"'
JSON.stringify('uDEAD')
// ↪ '"\udead"'So the string uDF06uD834 after processing with JSON.stringify() turns into \udf06\ud834. However, returning such invalid Unicode strings is unnecessary, because JSON strings can include Unicode escape sequences.
Legacy RegExp features
A specification for the legacy (deprecated) RegExp features in JavaScript, i.e., static properties of the constructor like RegExp.$1 as well as the RegExp.prototype.compile method.
The proposal includes another feature that needs consensus and implementation experience before being specced:
RegExplegacy static properties as well asRegExp.prototype.compileare disabled for instances of proper subclasses ofRegExpas well as for cross-realm regexps.
String prototypes .trimStart() & .trimEnd()
For consistency with padStart/padEnd the standard functions will be trimStart and trimEnd, however for web compatilibity trimLeft will alias trimStart and trimRight will alias trimEnd.
const one = " hello and let ";
const two = "us begin. ";
console.log(one.trimStart() + two.trimEnd());
// ↪ "hello and let us begin."New string prototype .matchAll()
matchAll() connote that all matches would be returned, not just a single match. It works as a .match() method with a global flag /g to locate all matches in the string, but returns an iterator:
const searchString = 'olololo';
// it returns the first occurrence with additional information about it
searchString.match(/o/);
// ↪ ["o", index: 0, input: "olololo", groups: undefined]
// it returns an array of all occurrences without additional information
searchString.match(/o/g);
// ↪ ["o", "o", "o", "o"]
// it returns an iterator
searchString.matchAll(/o/);
// ↪ {_r: /o/g, _s: "olololo"}
// The iterator returns each subsequent occurrence with detailed information,
// as if we were using .match without a global flag.
for (const item of searchString.matchAll(/o/)) {
console.log(item);
}
// ↪ ["o", index: 0, input: "olololo", groups: undefined]
// ↪ ["o", index: 2, input: "olololo", groups: undefined]
// ↪ ["o", index: 4, input: "olololo", groups: undefined]
// ↪ ["o", index: 6, input: "olololo", groups: undefined]The argument of matchAll() must be a regular expression, otherwise an exception will be thrown:
'olololo'.matchAll('o');
// ↪ Uncaught TypeError: o is not a regexp!Flatten a multi-dimensional array into a single level with .flat() & .flatMap()
The array prototype got .flat() and .flatMap(), which are generally similar to the implementation in lodash, but still have some differences. Optional argument - sets the maximum tree traversal depth:
const deepArray = [
'≥0 — first level',
[
'≥1 — second level',
[
'≥2 — third level',
[
'≥3 — forth level',
[
'≥4 — fifth level'
]
]
]
]
];
// 0 — returns an array without any changes
deepArray.flat(0);
// ↪ ["≥0 — first level", Array(2)]
// 1 — default deep value
deepArray.flat();
// ↪ ["≥0 — first level", "≥1 — second level", Array(2)]
deepArray.flat(2);
// ↪ ["≥0 — first level", "≥1 — second level", "≥2 — third level", Array(2)]
deepArray.flat(100500);
// ↪ ["≥0 — first level", "≥1 — second level", "≥2 — third level", "≥3 — forth level", "≥4 — fifth level"].flatMap() is an equivalent to a sequential call of .map().flat(). The callback function passed to the method must return an array that will become part of a common flat array:
['Hello', 'World'].flatMap(word => [...word]);
// ↪ ["H", "e", "l", "l", "o", "W", "o", "r", "l", "d"]
['Hello', 'World'].map(word => [...word]).flat()
// ↪ ["H", "e", "l", "l", "o", "W", "o", "r", "l", "d"]Also note that .flatMap(), unlike .flat(), does not have a depth argument. So only the first level will be flatten.
TL;DR: Conclusion
Stage 4 doesn't have huge changes, but Stage 3 is of more interest. Most of the features have already been implemented in Chrome, with the exception of Object.fromEntries(), the presence of which is not critical. But private class properties are very much awaited.
Original: EcmaScript 10 — JavaScript в этом году (Russian)
ResourcesClick to expand/shrink
