What is Redis?
Redis, which stands for Remote Dictionary Server, is a fast, open-source, in-memory key-value data store for use as a database, cache, message broker, and queue. The project started when Salvatore Sanfilippo, the original developer of Redis, was trying to improve the scalability of his Italian startup. Redis now delivers sub-millisecond response times enabling millions of requests per second for real-time applications in Gaming, Ad-Tech, Financial Services, Healthcare, and IoT.
How does Redis work?
All Redis data resides in-memory, in contrast to databases that store data on disk or SSDs. By eliminating the need to access disks, in-memory data stores such as Redis avoid seek time delays and can access data in microseconds. Redis features versatile data structures, high availability, geospatial, transactions, on-disk persistence, and cluster support making it simpler to build real-time internet scale apps.
Redis vs Memcached
Both Redis and MemCached are in-memory, open-source data stores. Memcached, a high-performance distributed memory cache service, is designed for simplicity while Redis offers a rich set of features that make it effective for a wide range of use cases.
| Feature | Memcached | Redis |
|---|---|---|
| Sub-millisecond latency | Yes | Yes |
| Developer ease of use | Yes | Yes |
| Data partitioning | Yes | Yes |
| Support for a broad set of programming languages | Yes | Yes |
| Advanced data structures | - | Yes |
| Multithreaded architecture | Yes | - |
| Snapshots | - | Yes |
| Replication | - | Yes |
| Transactions | - | Yes |
| Pub/Sub | - | Yes |
| Geospatial support | - | Yes |
They work with relational or key-value databases to improve performance, such as MySQL, Postgres, Aurora, Oracle, SQL Server, DynamoDB, and more.
Benefits of Redis
In-memory data store
All Redis data resides in the server's main memory, in contrast to databases such as PostgreSQL, Cassandra, MongoDB and others that store most data on hard disk or on SSDs. In comparison to traditional disk based databases where most operations require a roundtrip to disk, in-memory data stores such as Redis don't suffer the same penalty. They can therefore support an order of magnitude more operations and faster response times. The result is - blazing fast performance with average read or write operations taking less than a millisecond and support for millions of operations per second.
Flexible data structures
Unlike simplistic key-value data stores that offer limited data structures, Redis has a vast variety of data structures to meet your application needs. Redis data types include:
- Strings: text or binary data up to 512MB in size;
- Lists: a collection of Strings in the order they were added;
- Sets: an unordered collection of strings with the ability to intersect, union, and diff other Set types;
- Sorted Sets: Sets ordered by a value;
- Hashes: a data structure for storing a list of fields and values;
- Bitmaps: a data type that offers bit level operations;
- HyperLogLogs: a probabilistic data structure to estimate the unique items in a data set.
Simplicity and ease-of-use
Redis simplifies your code by enabling you to write fewer lines of code to store, access, and use data in your applications. For example, if your application has data stored in a hashmap, and you want to store that data in a data store, then you can simply use the Redis hash data structure to store the data.
A similar task on a data store with no hash data structures would require many lines of code to convert from one format to another. Redis comes with native data structures and many options to manipulate and interact with your data. Many programming languages support Redis and over a hundred open source clients are available for Redis developers.
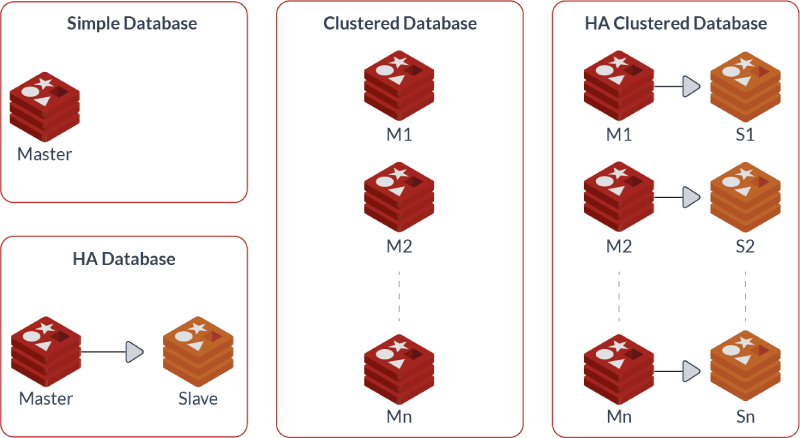
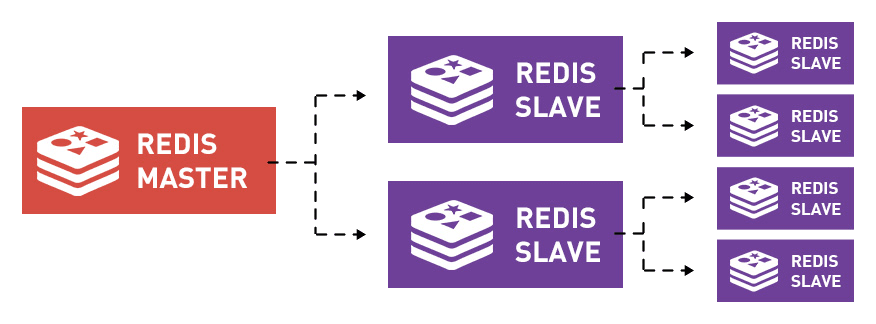
Replication and persistence
Redis employs a primary-replica architecture and supports asynchronous replication where data can be replicated to multiple replica servers. This provides improved read performance (as requests can be split among the servers) and faster recovery when the primary server experiences an outage. For persistence, Redis supports point-in-time backups (copying the Redis data set to disk).
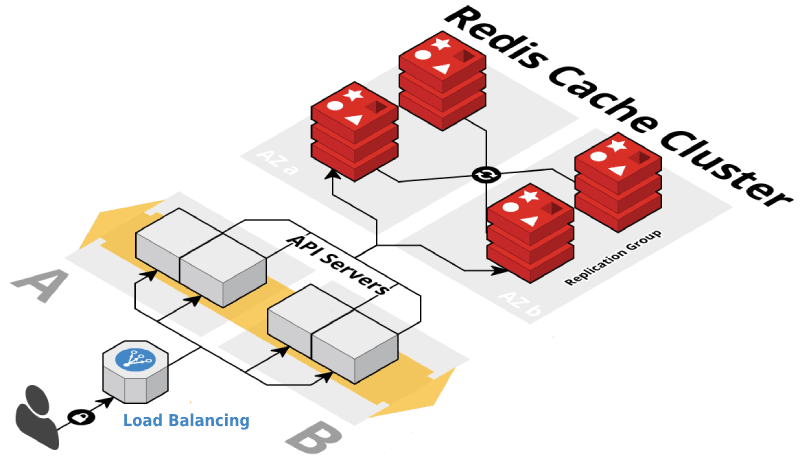
High availability and scalability
Redis offers a primary-replica architecture in a single node primary or a clustered topology. This allows you to build highly available solutions providing consistent performance and reliability. When you need to adjust your cluster size, various options to scale up and scale in or out are also available. This allows your cluster to grow with your demands.
Extensibility
Redis is an open source project supported by a vibrant community. There's no vendor or technology lock in as Redis is open standards based, supports open data formats, and features a rich set of clients.
Popular Redis Use Cases
Caching
Redis is a great choice for implementing a highly available in-memory cache to decrease data access latency, increase throughput, and ease the load off your relational or NoSQL database and application. Redis can serve frequently requested items at sub-millisecond response times, and enables you to easily scale for higher loads without growing the costlier backend. Database query results caching, persistent session caching, web page caching, and caching of frequently used objects such as images, files, and metadata are all popular examples of caching with Redis.
Chat, messaging, and queues
Redis supports Pub/Sub with pattern matching and a variety of data structures such as lists, sorted sets, and hashes. This allows Redis to support high performance chat rooms, real-time comment streams, social media feeds and server intercommunication. The Redis List data structure makes it easy to implement a lightweight queue. Lists offer atomic operations as well as blocking capabilities, making them suitable for a variety of applications that require a reliable message broker or a circular list.
Gaming leaderboards
Redis is a popular choice among game developers looking to build real-time leaderboards. Simply use the Redis Sorted Set data structure, which provides uniqueness of elements while maintaining the list sorted by users' scores. Creating a real-time ranked list is as easy as updating a user's score each time it changes. You can also use Sorted Sets to handle time series data by using timestamps as the score.
Session store
Redis as an in-memory data store with high availability and persistence is a popular choice among application developers to store and manage session data for internet-scale applications. Redis provides the sub-millisecond latency, scale, and resiliency required to manage session data such as user profiles, credentials, session state, and user-specific personalization.
Rich media streaming
Redis offers a fast, in-memory data store to power live streaming use cases. Redis can be used to store metadata about users' profiles and viewing histories, authentication information/tokens for millions of users, and manifest files to enable CDNs to stream videos to millions of mobile and desktop users at a time.
Geospatial
Redis offers purpose-built in-memory data structures and operators to manage real-time geospatial data at scale and speed. Commands such as GEOADD, GEODIST, GEORADIUS, and GEORADIUSBYMEMBER to store, process, and analyze geospatial data in real-time make geospatial easy and fast with Redis. You can use Redis to add location-based features such as drive time, drive distance, and points of interest to your applications.
Machine Learning
Modern data-driven applications require machine learning to quickly process a massive volume, variety, and velocity of data and automate decision making. For use cases like fraud detection in gaming and financial services, real-time bidding in ad-tech, and matchmaking in dating and ride sharing, the ability to process live data and make decisions within tens of milliseconds is of utmost importance. Redis gives you a fast in-memory data store to build, train, and deploy machine learning models quickly.
Real-time analytics
Redis can be used with streaming solutions such as Apache Kafka and Amazon Kinesis as an in-memory data store to ingest, process, and analyze real-time data with sub-millisecond latency. Redis is an ideal choice for real-time analytics use cases such as social media analytics, ad targeting, personalization, and IoT.
Original: Redis | AWS
ResourcesClick to expand/shrink
